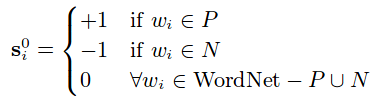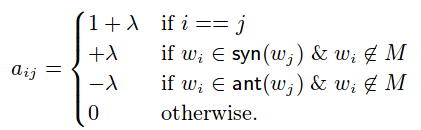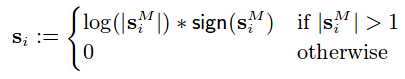Put in simple words: The paper describes a system to do aspect-based summarization of reviews for a service (like restaurant or hotel). Here, the aspects might refer to the aspects of service like food, value, hygiene in case of a restaurant. This model also has the ability to use the user provided labels/ratings when they are present and certain specific characteristics of service reviews to improve the result quality. Aspect based summarization helps customers compare different options on the available criterias according to their preferences and thus improving their experience.
Input/Output for the system
Input: A set of reviews for a given entity, in some domain. Eg. reviews for a hair salon, or reviews for a local restraunt.
Output: A set of relevant aspects along with aggregate scores for each aspect and supporting textual evidence.
Basic Idea
For any queried service S (with corresponding set of reviews R), the system consists of:
SENTI = Identify sentiment bearing text fragments (phrases or sentences) in R
ASPECTS = Identify relevant aspects of S in set SENTI.
Aggregate sentiment over each aspect.
Observation 1: A large number of queries for online reviews pertain to a small number of service types.
Observation 2: Nearly all services share basic aspects with one another in terms of reviews, such as value for money and quality of service.
Step 1: Identifying sentiment bearing fragments
Extract all sentences for a service.
Classify each of these as being positive, negative or neutral. (Note: Positive reviews frequently include negative opinions on aspects and vice versa.)
Start from small seed sets for Positive, Negative and Neutral sentiments (append the POS tag in order to help distinguish wordsense in the following steps)
Expand this through synonym and antonym links in WordNet. We also wish to assign each member a weight of confidence measure, that represents how likely the given word is positive or negative.
Define sm that will encode sentiment word scores for every word. The vector will be updated iteratively, hence the superscript. Initialize s0 as:
Furthermore, define adjacency matric A = (aij) as (with lamda < 1):
Sentiment scores are then propagated through the graph via repeated multiplication of A with score vector si to obtain sm (augumented with sign-correction function for seed words to compensate for realtions which are less meaningful in context of reviews).
M=5 and lambda=0.2 was used by the author.
Final score vector s is dereived by logarithmically scalling sM as follows:
Using this bootstrapped lexicon, classify the sentenses/text fragments x = (w1,w2,w3….wn) as follows. We also use a negation detector to reverse sign of si in cases where it is preceeded with a negation term like not:
raw-score(x) = SUM(si)
When
raw-score(x)
is under a given threshold, x is classified as neutral, otherwise as positive or negative depending on the sign.
Purity(x) is another metric that we define to give a measure of bias strength of x.
purity(x) = raw-score(x)/SUM(|si|)
Instead of using just the lexicon-based classifier using the raw-scores, the author manually labelled ~4k sentences as training data since the lexicon-based classifiers do not exploit any local or global context - which is generally good for performance. The features for the MaxEnt classifiers, that was used to predict ratings given a review, are described below. Say a review r = (x1,x2,x3…xm), where the x are the sentences.
raw-score(xi) and purity(xi)
raw-score(xi+1) and purity(xi+1)
raw-score(xi-1) and purity(xi-1)
raw-score( r ) and purity( r )
User provided rating for the text review, if present
Consider only the sentences that have a probability of being either positive or negative with some confidence threshold for further processing.
Step 2: Aspect Extraction
The authors use a hybrid approach, which is a mix of string based dynamic extractors and static aspects
Dynamic Aspect Extraction:
This solely relies on the text contained in the review to determine the ratable aspects of a service. This helps us identify the unique aspects of entities where either the aspect or entity type would be too sparse to include in the static models (eg. fish tacos at a restraunt)
This is implemented by identifying short strings that appear with high frequency in the SENTI, using filters of syntactic patterns. (Eg. JJ-NN-NN or JJ-NN-anything that occur in sentiment bearing sentences). These are then filtered by removing candidates composed of stopwords or those that are rare.
The candidate aspects that do not have sufficient mentions alongside sentiment bearing words are also dropped.
These are them stemmed and ranked according to a score s: weighted sum of their frequency in snetiment beaing sentences
Static Aspect Extraction:
Dynamic aspect extraction fundamentally suffers from the problem that aspects are fine-grained and their is no way to figure out if mediterranean lamb or crispy chicken refers to food.
A way out of the above problem is to learn a mapping from string mentions to coarse-grained aspects using hand-labelled training examples. This is clearly not possible (since it involves learning from dataset of all possible aspects for all possible services). However, as noted in observation 1, we only need to do it for a few services to acheive a performance improvement - restaurant and hotel. Also from observation 2, some aspects may actually be extendable to other service types too.
To learn this mapping, first the authors identify a few coarse-grained features for the restaurants (food, decor, service, value, other) and for hotels (rooms, location, dining, service, value, other). They then randomly selected ~1500 sentences and manually tagged them. Note each sentence can also be tagged to multiple aspects. They then trained a binary MaxEnt classifier for each aspect of each service type. Thus, we can now go from sentences containing fine-grained aspects to the actual coarse-grained aspects they point to.
To combine the aspects obtained from bothe the methods, we first remove any relevant static aspects from the dynamic aspects. Drop from bothe lists any aspects where the score of the aspect (if obtained dynamically) is less than a manually tuned threshold. The final set of aspects contain all the leftover static aspects. Add dyamic aspects to this list in descending order of their scores until either: dynamic aspects list is exhausted, or scores fall below manually tuned threshold or the number of aspects exceeds a manually tuned max. number of aspects.
Step 3: Aggregator/Summarizer
From the above steps, we have {S,P,A,C,L}:
S: set of non-neutral, sentiment-bearing sentences
P: Polarity scores for each sentence i
A: relevant aspects to summarize
C: scores for each sentence under each aspect. For aspects from static classifier Cia is 1 if the classifier for aspect a classified sentence i as belonging to that aspect else 0. For dynamic aspects, this is 1 if the sentence contains a token which is a stem level match for the aspect, else 0.
L: desired length of summary in terms of max. number of sentences to display in each aspect
To get a summary we follow the algorithm below:
for 1 to L; for each aspect a:
if all sentences s, that have Csa>0 have been included in summary, go to next l;
proportional to the positive-negative presence of aspect a, sample d from {1, -1}. Of the sentence not included in summary that have Csa > 0, choose the sentence that maximizes d*Pi, i.e. the most negative/positive sentence belonging to aspect a and ass it to summary.
The generated output is the summary text.
Discussion
Since the paper uses a lot of hybrid approaches, it becomes difficult to mathematically reason about the approach. Also, since there is no good way of scoring the generated review summaries, it becomes difficult to gauge how well the authors have actually performed (which might not be well represented by the sample result text in the paper) - though it seems very promising. The assumption that “service” and “value” aspects, whose review summaries are generated using the static methods, works well in case of services but this is exactly what makes this approach difficult to extend to products or other things. Also, there are places where we can easily improvise and perform better such as the combining of static and dynamic features, where instead of just a string match to identify similar features, we can do much more to identify any redundant aspects. Apart from these, judging from the generated summaries, which is afterall all we care about, this approach starts looking extremely good. A few improvements over this can definitely start looking promising for a system to be put to use.