

One of the most popular impossibility result in the world of distributed computing, the CAP Theorem has frequently confused people and has been misinterpretated by many. In here, I try to write in layman terms what the theorem means and what are its implications in your choice of systems.
We often hear people stating the CAP Theorem states as:
Of three properties:
only two can be satisfied simultaneously.
This statement however places C, A and P in equal terms, which is bit of a mistake. Also, having any or all of these properties are not actually binary choices and hence stating the theorem as above is some way exploiting language! One needs to understand what underlying meaning behind the terms is. So, lets jump into the crux of it. We will go into the topic in the following order for peadagogical purposes:
Abstractions, fundamentally are ways of taking a system, shredding the unnecessary things from it, presenting the rest in a more manageable fashion and calling it another system. A System Model is the description of these abstractions that are built into the systems and the ones that aren’t. Any distributed algorithm attains its objectives within the purview of these system specifications.
Fault Model similarly is the specification of kinds of faults we might expect in our system and thing that our distributed algorithm must be capable of handling.
In general, the description of both can be specified by answering the following questions:
As stated previously, the CAP theorem states that of three properties:
only two can be satisfied simultaneously
However, the notion of ‘2 out of 3’ is greatly misleading (as also pointed by Eric Brewer - who first put forth this conjecture). The reason for this is two-fold:
If the things, don’t yet look clear to you, keep moving as we try to clear the smoke of the air.
If querying any node in the cluster returns you the same result, it is said to be consistent. However, this is the strongest form of consistency. In CAP, the C means … surprize, surprize …. linearizability.
Consistency, more generally speaking, can be divided into:
* Strong Consistency:
* Linearizability: all operations appear to have executed atomically in an order that is consistent with the global real-time ordering of operations
* Sequential Consistency: all operations appear to have executed atomically in some order that is consistent with the order seen at individual nodes and that is equal at all nodes.
While linearizability requires order in which operation take effect to be equal to the actual real time ordering of operations, sequential consistency allows their reordering as long as order observed at each node remains consistent with each other and with that of their individual program orders. The difference, clearly is irrelevant and not noticeable to the end user interacting with the system.
A system is said to be available under a fault scenario when it continues to function through failures or that fault scenario. That is, a system serving requests even though one or more components of it might have crashed or failed is said to be available under that fault scenario. As consistency, availability again is not binary because of the term fault scenario. A system might be able to handle one or more kinds of faults that occur. While the CA kind of systems (mentioned in the section below) cannot handle any node failures, a CP system of 2n+1 nodes can handle upto n non-byzantine faults (that is it continues to function as long as the majority of n+1 can be maintained)
While, we may choose between C and A, partition tolerance or P has to be either provided by abstractions underneath (i.e. assumed to be present) or should be taken to be absent. Also, while there is no partition, the system can be both consistent and available. It is at the time of partition in a distributed system that we have to choose between strong consistency and availability.
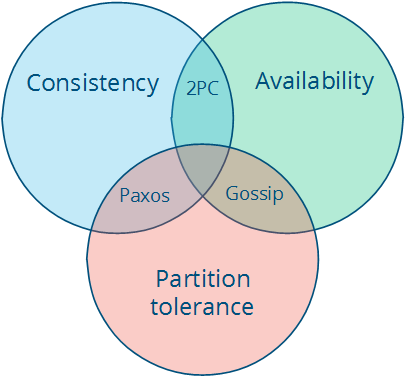
CA systems: If we assume that there are no partitions that are going to occur or that we may not need to be resilient to them and we might be able to offer the CA form of a system. Examples of these include any full strict quorum kind of systems such as a 2-phase commit or 3-phase commit. The C and A are fairly obvious in these. However, a node failure (which cannot be distinguished from the network failure to that node) can be said to result in a partition, under which the CA system halts to remain consistent. So, frankly the A in here serves no real value. (If you are not sure what 2-phase commit and 3-phase commits are, let me know in the comments and I might write another post on it :-) )
CP systems: These include systems with majority quorum protocols such as Raft or Paxos. In these, since the decisions are made by the majority only the majority partition remains available, while the nodes in the minority partition are rendered unavailable.
AP systems: Any system that can resolve conflicts in incosistent data is a good example of this kind (such as Amazon Dynamo). Since the system continues to function through the network partition, different parts of it might have different data and hence the inconsisteny resolution is required.
This is depicted below:
src: Distributed Systems for fun and profit
The intuition behind cap theorem is fairly straightforward once understood. Hopefully, the following illustration helps this understanding:
Consider two nodes that form a distributed system. Say, A and B. When there is a network partition between them, they cannot communicate. At this point you can either, we are left with two choices:
Allow the nodes to get out of sync (giving up consistency), or
Consider the system to be “down” (giving up availability)
In any distributed system, at the time of partition, the choice between C and A is binary only when dealy with strong form of consistency
It is possible to be both available and consistent at times, when there are no network partitions. Hence, choosing CP or AP during a partition doesn’t imply that the system is not available or consistent at other times.
We might be able to attain both availability and consistency during a network partition, should we be okay with weaker forms of consistency.
In the end, a good rephrasing of the CAP theorem from above might be as follows: In a distributed data store, at the time of network partition you have to chose either Consistency or Availability and cannot get both. (src: SO ans)
Feel free to comment your doubts or discussions in comments section below.