

With increasing scale of services and their increasing complexity, managing vastly distributed services (or even many different services which might not be distributed) has become challenging. Logs are pervasive data sources that contain useful information about the health or abnormalities in the normal functioning of these processes. However, the ratio of noise to useful information in the log files is usually very high, which renders this way of health estimation tiresome. Drain, which forms a part in the highly regarded log parsing algorithm, provides an efficient way of reducing these millions or even billion lines of log files into a few recurring and useful log templates which can then be used to train an anomaly detection model or even highlight useful information in case of an unhealthy services. This technique is summarised below.
08/11/09 204608 Receiving block blk_3587 src: /10.251.42.84:57069 dest: /10.251.42.84:50010
08/11/09 204655 PacketResponder 0 for block blk_4003 terminating
08/11/09 204655 Received block blk_3587 of size 67108864 from /10.251.42.84
blk_3587 Receiving block * src: * dest: *
blk_4003 PacketResponder * for block * terminating
blk_3587 Received block * of size * from *
More loosely defined, the primary goal of log parsing is to distinguish between constant and variable part from the log contents, while also achieving clustering to a reasonable extent.
Why Do This:
Expectations:
Structure of the Tree:
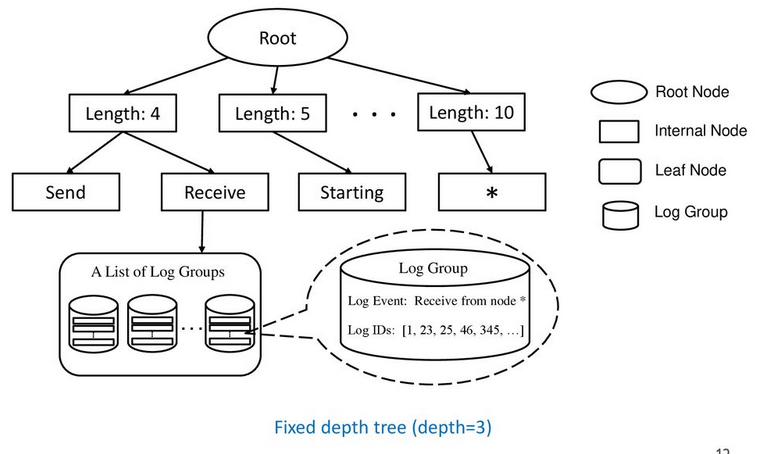
Stage 3: Search by Preceding Tokens: Drain then traverses from 1st layer node from step 2 to a leaf node based on the tokens in the beginning of the log line (consuming one token at each level) - this is again based on a assumption that the beginning tokens of a log message are more likely to be constants.
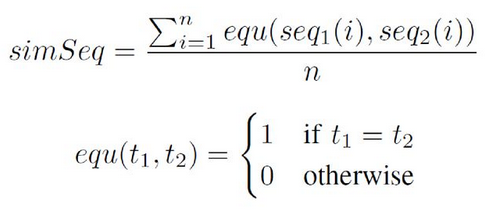
If the similarity is greater than the similarity threshold then it is assigned to the most suitable log group, otherwise it forms a new log group.
Stage 5: Update the parse tree: The ID/log line is added to the most suitable log group (or new log group) in the corresponding cases. In case this log line matched to a suitable log group, the log event/template is also updated as follows:
Time complexity of Drain is O( (d+cm)n ) which is essentially linear.
Drain has proven to be an effective, accurate and efficient online log parsing algorithm. It has tuned out to give extremely good accuracy scores as compared to other log parsing algorithms on similar datasets. This has also turned out to be effective in real world AD scenarios as the author points out in the case study.
On a personal experience front, we had one opportunity of being able to use a log parsing system, while working on an overnight Nokia Log Anomaly Detection Hackathon in 2018. The repository for the same can be found here. A preprocessing step, such as log parsing using Drain gave us great head start and we could secure the winners position on the Hackathon. We did try a few other popular log parsing methods, however finally decided to stick to DRAIN given our f1-score results. The other contributor was Mayank Rajoria.